深層モデルのパラメータを一列に並べてベクトルにします。このベクトルは大規模なモデルであれば何十億次元にもなります。一見、意味のない数値の羅列のようですが、このベクトルはベクトルとして深い意味があることが分かってきています。例えば、 と
を異なるパラメータベクトルとすると、
モデルスープ
モデルスープ [Wortsman+ ICML 2022] は複数のモデルパラメータを平均することで性能を上げる手法です。事前学習モデル からはじめて、様々なハイパーパラメータで訓練した結果のパラメータを
とします。これらを平均したベクトル
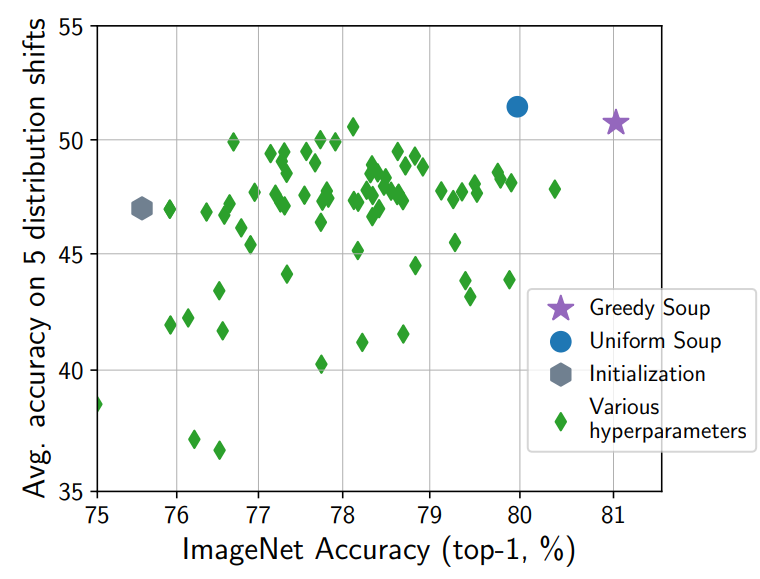
典型的な訓練の手順では、様々なハイパーパラメータで訓練したあと、検証用データで性能を評価し、最も良かったモデルを残しそれ以外は破棄します。モデルスープは本来破棄していたはずのモデルも材料として活用して性能を上げられることが利点です。追加の訓練時間も必要ありません。また、検証用データセットが必要無い点も魅力的です。
モデルスープはアンサンブルと似ていますが、推論時間とデプロイの単純さの点で大きな違いがあります。 個のモデルをアンサンブルすると、推論時間は
倍になりますが、モデルスープでは通常のモデルと推論時間は変わりません。また、実環境にデプロイする際、アンサンブルでは複数のモデルを管理する点で煩雑になりますが、モデルスープでは単一のモデルに統合されているため、通常のモデルと同じようにデプロイできます。
上に述べた方法は一様スープと呼ばれる最も簡単なバージョンです。貪欲スープと呼ばれるバージョンでは、検証用データセットを用いて、モデルを検証性能の良い順番に並べ、一つずつスープ(集合)に追加していきます。最初は最も検証性能の良いモデルだけがスープに入っています。ここに検証性能の良い順にモデルを入れ、スープ内のパラメータの平均を取ったモデルの検証精度が上がるならば追加を正式に決定し、下がるならば追加するのを取りやめます。全てのモデルの処理が終わったあとの、スープ内のパラメータの平均を取ったものが最終的なモデルです。貪欲スープは検証用データが必要で、手順も少し複雑になりますが、一様スープよりも性能が良いことが確認されています。
モデルスープに加えられるモデルは全て同じ事前学習モデルからファインチューニングしたものであることに注意してください。一般に、異なるランダム初期化パラメータから始めて訓練したモデルどうしの平均を取っても良いモデルにはなりません。これは、直観的には、異なるランダム初期化パラメータではモードの整合性が無いため、単純に平均するとめちゃくちゃなことになるからです。具体的には、ニューラルネットワークの順列不変性が重要な役割を果たすことが知られています [Entezari+ ICLR 2022]。ニューラルネットワークのニューロンは適当に並び替えてもモデルの関数としての振る舞いは変化しません(下図)。しかし、この並べ替えによりパラメータは次元が入れ替わり、ベクトルとしては全く別のものになります。異なるランダム初期化パラメータから始めたモデルではこの並び替え方が合っていないので、別の次元を別の次元と平均することになり、結果がめちゃくちゃになります。Git Re-Basin [Ainsworth+ ICLR 2023] という手法は、ニューロンのマッチング問題を解くことで、並び替え方が合っていないモデルどうしを整列します。異なるランダム初期化パラメータから始めたモデルでであっても、Git Re-Basin を行ってから平均を取ると、良いモデルになることが確認されています。

確率的重み平均 (stochastic weight averaging; SWA) [Izmailov+ UAI 2018] もモデルスープと同様に、パラメータの平均を取ることで性能を上げる手法です。確率的重み平均では、学習後にある程度大きな学習率で SGD を走らせ、モデルパラメータの列 を得て、これらを平均します。1 回の学習パスで作れるお手軽なモデルスープと見なすこともできます。
モデルスープはアンサンブルの近似と見なすことも可能です。 をモデルの表現する関数とします。アンサンブルは
タスクベクトル
タスクベクトル [Ilharco+ ICLR 2023] は、タスクの学習を表すベクトルです。タスクの学習や忘却 (unlearning) をタスクベクトルの算術により実現できます。
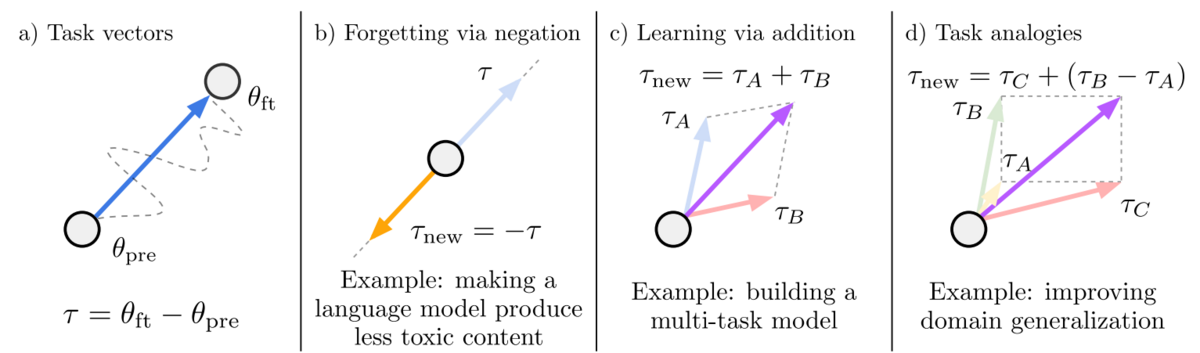
事前学習モデル からはじめて、タスク A のデータセットでファインチューニングした結果を
としたとき、
をタスク A のタスクベクトルといいます。
タスクベクトルの算術により学習や忘却が実現できることが知られています。例えば、パラメータ が表すモデルは、タスク A と B の両方の性能が高くなります。また、事前学習モデルを言語モデル、タスク C を悪口をいうタスクとし、悪口から構成されるテキストコーパスで学習をしてタスクベクトル
を得たとき、パラメータ
が表す言語モデルは悪口を言わないモデルになります。
また、面白いことに、単語ベクトルと同じようにタスクベクトルもタスクの類推処理ができます。単語ベクトルでは、king - man + woman ≈ queen となることが知られていますが、これと同様のことがタスクベクトルでもできるのです。例えば、タスク A を Amazon レビューの言語モデリング、タスク B を Yelp レビューの言語モデリング、タスク C を Amazon の感情分析とすると、パラメータ が表すモデルは Yelp レビューの感情分析で良い性能を達成します。他にも、タスク A を犬の写真データ、タスク B をライオンの写真データ、タスク C を犬のイラストデータとすると、パラメータ
が表すモデルはライオンのイラストを正しく分類できます。このように、所望のタスクのデータを全く、あるいは少量しか持ち合わせてない場合にも、異なるドメインのデータにより構成したタスクベクトルの演算により、所望のタスクを解けるようになるのです。
モデルパラメータとニューラルタンジェントカーネル
このようなモデルパラメータの算術はニューラルタンジェントカーネル (Neural Tangent Kernel; NTK) を考えると見通しが良くなります [Ortiz-Jimenez+ NeurIPS 2023]。
事前学習モデルのパラメータを としたとき、このモデルで定義されるニューラルンタンジェントカーネル
とは、
確率的勾配降下法 (SGD) によりファインチューニングを行い、
訓練の過程であまりパラメータが動かなかったとし、 の周りの
についてのテイラー展開により一時近似すると、パラメータ
が表す関数は
また、モデルパラメータ更新の履歴を展開すると、
特定のテストサンプル についての議論ではなく、関数

は負の値もとる。)
ここまでくると、(1) 訓練データ、(2) モデルパラメータ、(3) モデルが表す関数、の関係が明瞭になります。訓練データは という項を通じて、モデルパラメータに影響を与えます。これは、関数値を変化させるべき量に応じて、訓練パラメータにそのサンプルのニューラルタンジェントカーネル特徴量
を足し合わせることに対応しています。また、これはモデルが表す関数という観点では、カーネル値
に応じて値を上下させていることに対応しています。
タスク A の訓練データ で訓練したモデルパラメータ
には、
中の訓練データのニューラルタンジェントカーネル特徴量が加えられています。タスク A のタスクベクトルは、ニューラルタンジェントカーネル特徴量の重み付き和になります。
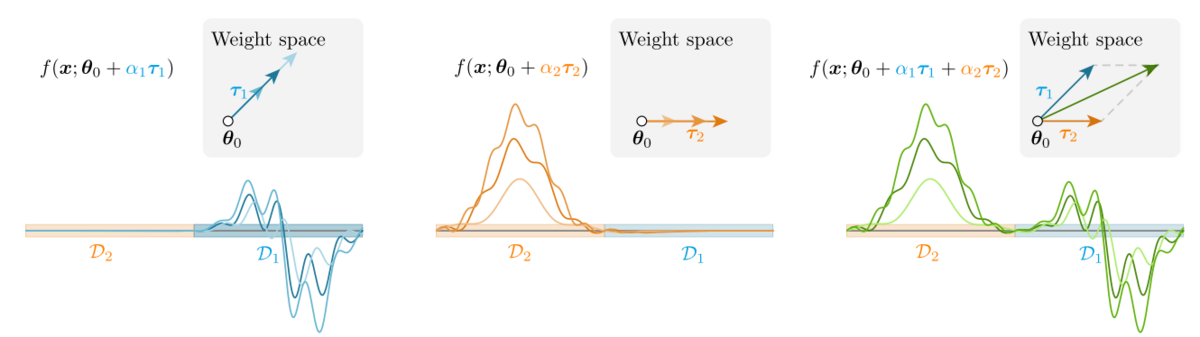
タスク A のタスクベクトルとタスク B のタスクベクトルの和は、タスク A のデータセットとタスク B のデータセットのニューラルタンジェントカーネル特徴量の和集合が加えられていることになります。これが、タスクベクトルの和により学習が起こる直観的な説明になります。
また、モデルスープについても、スープにニューラルタンジェントカーネル特徴量を追加していっていると見なすことができます。訓練データは同じなので、これでは恩恵は説明しきれていませんが、直観的にはハイパーパラメータ毎に少し異なる角度で特徴量が足し合わされるためにロバストに類似度を測れるようになっていると考えることができます。
おわりに
深層モデルのパラメータは意味のない数値の羅列のように考えがちですが、よく分析すると理論的にも実験的にも深い意味があるというのはとても面白いと思いました。ここ 1~2 年で急速に発展が進んだトピックであり、今後も面白い研究結果がどんどん出てきそうに思います。
連絡先: @joisino_ / https://joisino.net