")
講談社より『グラフニューラルネットワーク(機械学習プロフェッショナルシリーズ)』を上梓しました。
グラフニューラルネットワークはグラフデータのためのニューラルネットワークです。化合物やソーシャルネットワークのようなグラフデータの解析に使うことができます。また後で述べるように、テキストも画像もグラフなのでテキストや画像の分析にも使えますし、それらを組み合わせたマルチモーダルなデータにも適用できます。要は何にでも使うことができます。この汎用性がグラフニューラルネットワークの大きな強みです。
本稿ではグラフニューラルネットワークを学ぶモチベーションと、本書でこだわったポイントをご紹介します。
- グラフニューラルネットワークは何にでも使える
- 付加情報をグラフとして表現できる
- グラフニューラルネットワークは通常のニューラルネットワークの一般化である
- こだわり:専門用語の日本語訳
- こだわり:難易度順の配列
- おわりに
グラフニューラルネットワークは何にでも使える
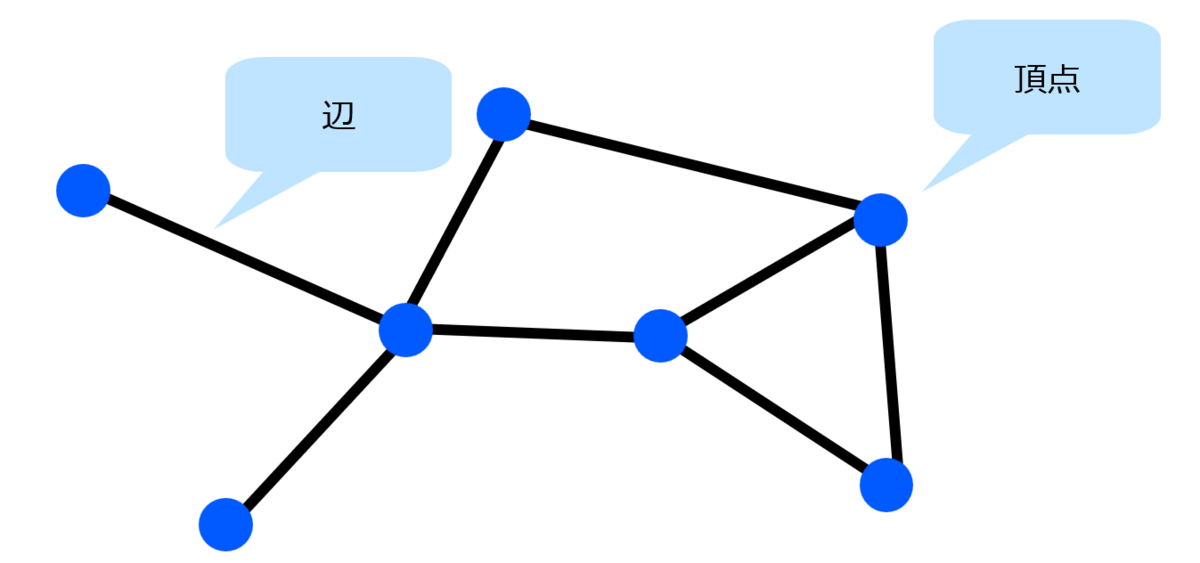
グラフはものごとの関係を表すデータ構造です。ものごとの基本単位を頂点といい、二つの頂点の間の関係を辺により表します。これだけだと非常に味気ないですが、具体的に頂点と辺の意味を定めることで様々なものごとを表すことができます。
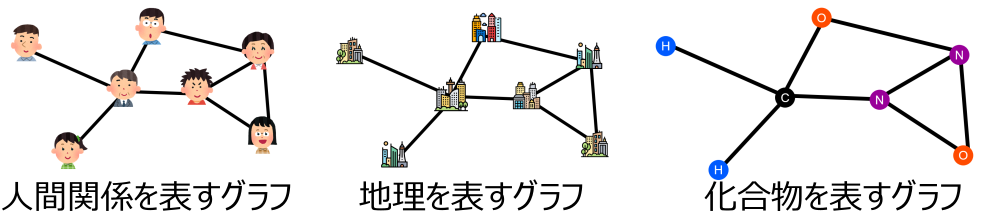
グラフニューラルネットワークはグラフとして表現されるこれらのデータ全てを統一的に扱うことができ、これらのデータの分類・回帰・生成など、さまざまなタスクを解くことができます。グラフニューラルネットワークを学ぶことで扱えるデータの範囲がグッと広がります。グラフニューラルネットワークの具体的な定義は本書を参照してもらうとして、ここではグラフニューラルネットワークには何ができるのかについてもっと詳しくみてモチベーションを高めていきましょう。
実は画像もグラフです。画素が頂点、画素の隣接関係が辺に対応します。
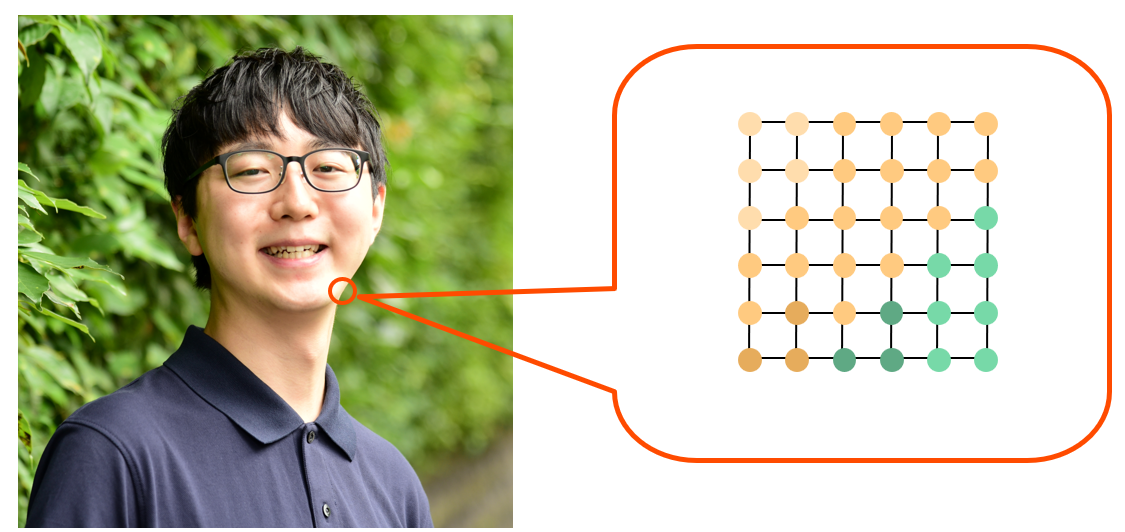
画像でよく使われる畳み込みニューラルネットワークはグラフニューラルネットワークの特殊例となっています。畳み込みニューラルネットワークは上下左右の 8 近傍から固定的に情報を集約しますが、グラフニューラルネットワークは一般に様々な位置から情報を集約します。この対応関係を念頭に置くと、畳み込みニューラルネットワークでの知見をグラフニューラルネットワークに活用することもできます。
Vision GNN: An Image is Worth Graph of Nodes [Han+ NeurIPS 2022] はグラフニューラルネットワークを画像データに適用した例です。この手法は画像パッチを頂点として、グラフニューラルネットワークを用いて畳み込みニューラルネットワークよりも柔軟に情報を集約します。実験では畳み込みニューラルネットワークやビジョントランスフォーマーよりも高い性能を達成しています。
付加情報をグラフとして表現できる
また、いろんな情報を簡単にくっつけることができることもグラフの強みです。例えば、一列で表されるテキストに、いろんな情報をくっつけたグラフを考えます。
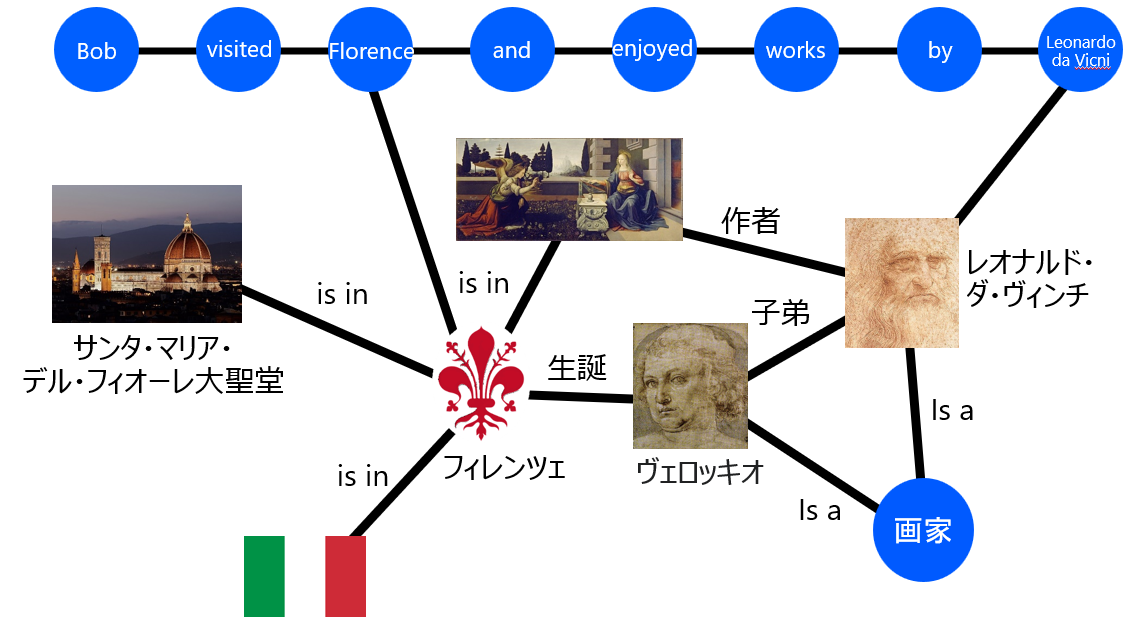
このグラフにグラフニューラルネットワークを適用することで、従来の手法よりもいろんな情報を考慮しながらテキストを分析できます。
既存の機械学習手法では、要素の特徴を固定長のベクトルとして表現することが一般的でしたが、特徴を固定長のベクトルとして表現するのが難しい場合もよくあります。グラフのように情報をくっつけていくのは固定長の特徴ベクトルを作るよりも簡単に実現できることが多いです。活用できずに眠っていたデータベースの別テーブルをとりあえずくっつけてみたり、ウェブから取得した補助情報をとりあえずくっつけてみて、グラフニューラルネットワークに入力すると、精度が上がったり、面白い分析結果が出てくるかもしれません。特徴の次元を増やすという以外に、グラフとしてくっつけて活用するというデータの利用方法を知っていると分析の幅が広がります。
グラフニューラルネットワークは通常のニューラルネットワークの一般化である
グラフニューラルネットワークは通常のニューラルネットワークの一般化になっています。上に述べたように、畳み込みニューラルネットワークはグラフニューラルネットワークの特殊例ですし、実はトランスフォーマーもグラフニューラルネットワークの特殊例です。上で紹介した Vision GNN はある意味でビジョントランスフォーマーの一般化になっています。
なので、既にお気に入りのニューラルネットワークアーキテクチャがあるんだよなという方も、そのアーキテクチャにグラフニューラルネットワークの要素を取り入れて進化させることができます。グラフニューラルネットワークの要素を取り入れて精度が良くなるかは活用するグラフの定義にかかっています。良い情報を含むグラフを定義できれば、精度を向上させることができる大チャンスです。仮にグラフニューラルネットワークの要素を取り入れて精度が上がらなかったとしても、特殊例である元のアーキテクチャに帰着すればよいだけなので、試してみる価値はあります。例えば、上で紹介した Vision GNN では、ハイパーパラメータ k が n のときにビジョントランスフォーマーとなり、k が n より小さいときに一般のグラフニューラルネットワークになります。ハイパーパラメータ探索の結果、k = n となり一般化した効果が得られない可能性もありますが、そうなったとしても損はしないですし、よりよい k が見つかり精度が上がる可能性があります。実際、Vision GNN の論文では小さい k を使うことでビジョントランスフォーマーよりも精度を向上させられています。
以上、グラフニューラルネットワークを学ぶメリットについて簡単に紹介しました。モチベーションが上がった方は本書でグラフニューラルネットワークを学んでいただければ幸いです。
以下では本書でこだわったポイントをご紹介します。
こだわり:専門用語の日本語訳
本書では専門用語を可能な限り日本語訳し、原語も併記しました。私の指導教員の鹿島先生や本書のシリーズ編者の杉山先生が専門用語は可能な限り日本語訳すべしという考えで、私も昔はしぶしぶ従っていたというのが正直なところなのですが、最近は日本語訳をするメリットが大きいと感じるようになり、積極的にこの方針を採用しています。(なおブログや口頭では日本語訳により硬くなりすぎるときにはカタカナで書いたり喋ったりすることもあります。)
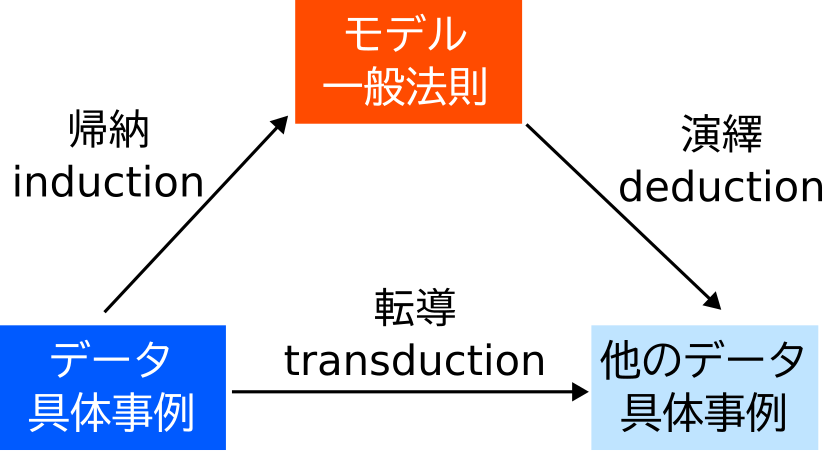
例えば、転導学習 (transductive learning) の訳にはこだわりました。転導学習とは、既知の具体的事例に基づいて、未知の具体的事例についての推論を行うことです。既存の日本語の文献ではトランスダクティブ学習と訳されていたのですが、日本人がトランスダクティブの意味を初見で取るのは不可能で、単なるおまじないになってしまうと考え、頑張って訳出しました。転導学習であれば既知の具体的事例を「転」じて、未知の具体的事例を「導」くということが単語だけからでもなんとなく見えてくると思います。英語では、induction, deduction, transduction と併記されることがよくあります。induction は既知の具体的事例に基づいて一般法則を導くこと、deduction は一般法則に基づいて未知の具体的事例についての推論を行うことです。induction は日本語では帰納、deduction は演繹と訳すのが定番です。帰納と演繹は明治時代に西周が訳出した語なのですが、現代人からするとこれらの意味が取りづらく、transduction をこれらとうまく整合させるのに苦労しました。演繹の演という字は、のべる、ひきのばす、おしひろめるということを表し、繹という字は糸口から糸を引き出すことを表しています。一般法則を糸巻きに見立てているのですね。帰納は逆に、糸巻き(一般法則)から出てきた糸(具体的事例)を糸巻きに「帰」し「納」めることを表しています。これらの訳は induction と deduction の接頭辞の in- と de- を見事に対比させています。しかし、-duce は導くという意味なのですが、演繹と帰納という訳語はこの部分の反映が弱いので意味が取りづらくなっています。また、現代人からすると糸巻きや「繹」という字に馴染みがないことも意味が取りづらいことも一因でしょう。そこで、trans- の転じるという部分と、-duce の導くをそのまま合わせて、転導という訳にしました。語根を意識して訳すと、原語の使い方が遷移したときにも訳語のニュアンスがずれにくいという点も一つの理由です。
一般に日本語の文献においては、「近年、transductive learning が…」< 「近年、トランスダクティブラーニング (transductive learning) が …」<「近年、転導学習 (transductive learning) が…」というように、原語のみ、カタカナ、日本語訳の順に良いと考えています。第一の不等式については、英語が読めなくてもスムーズに読み進められるという点でカタカナが優れています。ある程度英語ができる人であっても transductive を読むのに一瞬つっかえると思います。読み方に脳のリソースを取られるのは生産的でないです。些細な点ではありますが、著者が配慮をするだけで多くの読者が恩恵を受けられます。塵も積もって山となるです。第二の不等式は、前にも述べたように、日本人がトランスダクティブの意味を初見で取るのは不可能で、単なるおまじないになってしまうからです。転導学習であれば、既知の具体的事例を「転」じて、未知の具体的事例を「導」くということが初見でもなんとなく想像できます。また、和書は一切英語ができない人(数理だけは抜群の小中学生など)を救う面もあるので、できる限り英語を必要としないように構成するのが良いと考えています。こうすることで洋書との差別化や和書の意義もより明瞭になります。
悩んだのはカタカナや英語で書くことが完全に定着している場合です。本書のタイトルでもあるグラフニューラルネットワークはまさにその例です。グラフもニューラルネットワークもカタカナで表記することが定着しすぎているので、グラフ神経網や図神経網とするのはかえって分かりづらいと思いグラフニューラルネットワークとしました。また、定着度合いが中程度のものは併記することにしました。例えば、注意機構(アテンション)や長短期記憶 (LSTM) などは、英語が一切できない人のために日本語表記したい一方、カタカナに慣れている人にとっては日本語訳のみだとそのことを示していることが分かりづらいと思い、日本語訳とカタカタや英語を併記することにしました。
以上のように、訳語にもこだわったおかげで、とても読みやすくなったと思います。ぜひご堪能ください。
こだわり:難易度順の配列
本書の章節は難易度順に配列するよう心がけました。グラフニューラルネットワークの初心者が読み進めるうちにスムーズにステップアップして気付いたらグラフニューラルネットワークをマスターできるようになる本を目指しました。
前作の『最適輸送の理論とアルゴリズム』は本書と異なり、最初に基礎事項を固める配列を採用しました。これはこれで王道の配列方法ですし、数理に慣れ親しんだ方はこちらの方が読みやすいかもしれません。しかし、基礎イコール簡単というのは必ずしも成り立たず、基礎パートで挫折してしまった方もいたようです。
グラフニューラルネットワークは特に実応用が多いトピックなので、数理が苦手な人にも応用まで進んで欲しいと考え、章の並びも、章の中の節の並びも、難易度順になるように気を使いました。説明の流れもあるので、きれいに難易度順に並べるのは至難の業で、構成にはかなりの時間がかかりました。しかしそのおかげで、挫折がすくなく、それでいて読み終わったときには自然にステップアップできているような理想的な構成にできたと自負しています。
おわりに
本書はかなりの力作なので読んでいただければとても嬉しいです。読んで損はさせません。よろしくお願いいたします。
拙著『グラフニューラルネットワーク』の著者見本が届きました‼️
— 佐藤 竜馬 / Ryoma Sato (@joisino_) 2024年4月22日
機械学習に興味のある皆さんに楽しんでいただける本になったと思います
ぜひ読んでくださいねっhttps://t.co/awbS7SjUlV pic.twitter.com/KTrupPb07i
連絡先: @joisino_ / https://joisino.net