LLM の注意機構には色んな機能があることが分かっています。注意機構を分析することで、なぜ LLM は文脈内学習や思考の連鎖に成功し、ひいてはなぜ LLM が外挿に成功することがあるのかについての理解が得られます。本稿ではさまざまな種類の注意機構を観察することでこの問題をひも解きたいと思います。
目次
基本的な考え方
LLM の多くは注意機構と多層パーセプトロン (MLP) を交互に積み上げたアーキテクチャを持ちます。各層は複数の注意機構をもち、それぞれの機構を注意ヘッドと呼びます。
注意機構の役割は
- 文脈内の検索
- ルール・アルゴリズムの実現
です。文脈とはプロンプトと今までの出力のことで、これを踏まえて次トークン予測を行います。注意機構は文脈から次トークン予測に必要な情報を検索する役割を持ちます。
いくつかの注意ヘッドは特定のルールを持ち、そのような注意ヘッドが複数協調することで高度なアルゴリズムが実現することがあります。チューリングマシンのヘッドのような役割です。これにより、LLM は様々なプログラムを実行できる汎用的な計算装置のようになり、はじめて見る入力に対しても適切な処理を加えて出力できるようになります。
MLP の役割は
- 知識の貯蔵・抽出(= データベース)
- プログラムの実行
です。LLM の実行するタスクは単純な計算処理だけではなく、知識が必要なことがあります。LLM は MLP に知識を保存し、必要に応じて取り出して活用します。数学的には、パラメータ行列 を直交するベクトル成分を用いて
と分解して表現すると、ベクトル との積が
となることが分かります。つまり MLP の線形層に
を入れると
が出てきます。これは
をデータとするキーバリューストアのような役割を持ちます。事前訓練でこのキーバリューストアを構築したのち、推論時には凍結します。つまり、MLP の線形層は入力によらない静的なデータベースのような役割を果たします。なお余談ではありますが、LoRA により
と更新することは、新しいキー・バリューを挿入する(あるいは既存のキー・バリューを編集する)と解釈できます。
MLP はデータベースとしての役割に加えて、注意ヘッドが検索して取り出した入力情報と、前層がデータベースから取り出した内部知識をもとにした状態の変換、すなわち具体的なプログラムの実行という役割も受け持ちます。
つまり、LLM はチューリングマシン的な汎用計算装置 + 事前訓練により構築された静的なデータベースのような能力を持ちます。
ここから、LLM の限界と可能性が分かります。内部知識が必要なタスクについては、静的なデータベースに入っていない知識には答えられません。LLM のハルシネーションは、データベースがミスヒットしたにもかかわらず、そのままプログラムを実行して出力してしまった結果と考えられます。この意味で、知識については外挿はできません。一方、論理的に推論できるようなタスクについては、計算装置がプログラムを実行することで、訓練時に全く見ていない入力に対しても適切な処理を加えて出力できます。
この LLM の能力は古典的な N-gram 言語モデルと比較することでより際立ちます。N-gram 言語モデルによる次トークン予測は直近の入力の統計的情報に基づいています。「カレー」と「ライス」は共起しやすいので「カレー」トークンの次は「ライス」の可能性が高い、というような推論です。LLM はこのような統計的な予測に加えて、文法のようなルールや論理に基づいて次トークン予測をすることができます。
ここまで、本稿を通しての基本的な考え方を述べました。次は最も基本的な注意ヘッドである文法ヘッドを通して具体的な振る舞いを確認していきます。
文法ヘッド
LLM の一部の注意ヘッドは文法に基づくことが知られています。そのような注意ヘッドを文法ヘッドと呼びます。例えば、BERT の第 8 層の第 10 ヘッドは直接目的語から動詞へ注意し、第 8 層の第 11 ヘッドは装飾語から名詞へ注意することが観察されています [Clark+ 2019]。直接目的語ではないトークンや、装飾語でないトークンは、これらのヘッドでは [SEP] トークンに注意を向けます。(※正確に言えば BERT は LLM と言えるか微妙ではありますが、本稿では BERT も含めて考えます。)

定量的にも、第 8 層の第 10 ヘッドでは直接目的語のなかで当該動詞へ最も注意を向けたトークンの割合は 86.8% であり、第 8 層の第 11 ヘッドでは冠詞の中で装飾名詞に最も注意を向けたトークンの割合は 94.3% であり、かなりの割合でこのルールに従った注意が構成されていることが分かります。
このモデルは完全に教師なし(自己教師あり)で訓練されており、文法についての知識は明示的には一切与えていません。にもかかわらず教師なし学習の結果、自然にこのような注意パターンが形成されました。これはこのような文法ルールがトークン予測にとって本質的であり、文法ルールに基づくと効率よく、精度よく、トークン予測ができることを示唆します。他にもトークンを予測する方法はいくらでもあるはずですが、モデルは自由な探索の結果、このやり方が最も効果的であることを突き止めてこのような注意パターンを形成するようになったということです。
文法ヘッドが LLM の能力にとって重要であることが観察されています。訓練の初期には注意はランダムであり、文法ヘッドは存在しません。あるタイミングで文法ヘッドが突然現れ、その直後に LLM の文法能力が急激に増加することが観察されています [Chen+ ICLR 2024]。
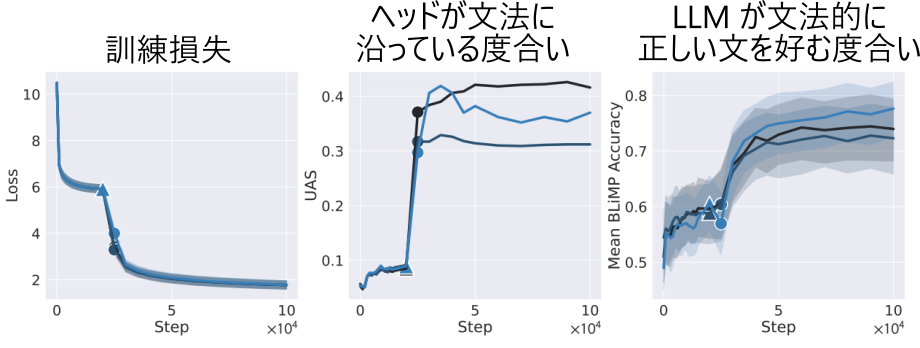
ヘッドが文法に沿っている度合いは各トークンが最も注意を向けているトークンを抽出し、これが構文木に沿っている割合により算出しています。上図中央のグラフより、この割合が訓練途中に急激に増加することが見てとれます。そしてこの直後に文法的に正しい文を好む度合いが急増しています。この数値は BLiMP という文法データセットにより算出しています。BLiMP は
- The cats annoy Tim.
- The cats annoys Tim.
のように、一方は文法的に正しいがもう一方は文法的に間違っているほとんど同じ文のペアからなるデータセットです。それぞれをモデルに入力し、どちらが尤度(生成されやすさ)が高いかを算出します。文法的に正しい方が生成されやすい割合が右のグラフです。この結果に示されるように、文法ヘッドが現れると文法のルールに従った文を生成できるようになります。このタイミングより前にも訓練損失自体は下がっているので、ある程度のトークン予測はできているはずですが、これは文法に基づかない、共起情報などを活用した統計的な予測と考えられます。このときにもそれらしい文が生成できることがありますが、文法を間違えていたり、論理的におかしいことがあります。文法ヘッドが登場してはじめて、より確実に、文法のルールに従って文を生成できるようになります。このようなルールが身につけば、訓練時に全く見たことがない文が入力されたとき、完璧に答えられるとまでは言わないまでも、文法に従ってある程度の推測をしながら適切な処理ができるようになると考えられます。
ここまで、最も基本的な文法ヘッドとその意義について紹介しました。
文法ヘッドでは直接目的語ではないトークンや、装飾語でないトークンは、これらのヘッドでは [SEP] トークンに注意を向けると述べましたが、[SEP] トークンのような注意の受け皿には特別な働きをする場合があることが知られています。注意機構の役割をより深く理解するべく、次は注意の受け皿について詳しく見ていきます。
注意の受け皿とレジスタトークン
LLM は入力テキストの最初の数トークンや、[SEP] などの特殊トークン、句読点などの記号に強い注意を向けることが観察されています。このように、多くのトークンから注意を受けるトークンを注意の受け皿 (attention sink) と言います。
注意の受け皿の意義の一つは、文法ヘッドが構文と無関係のトークンに対して注意の捨て場として使うように、当該ルールにおいて対応先が存在しないことを示すということです。
自己回帰型の言語モデルにおいて最初のトークンが受け皿になりやすいのは、自己回帰型のモデルは前方向にしか注意を向けられず、前の方に受け皿が必要だからだと考えられます。
注意の受け皿はこれに加えて、グローバルな情報を一時的に格納したり、他のトークンと情報をやり取りするバッファとして使われることがあります。特殊トークンや句読点はトークン自体の意味はほとんどありません。これらのトークンの内部状態にトークン自体の情報を込める必要はほとんどなく、容量に余裕が生じます。モデルはこの空き地を効率的に活用し、当該トークン以外の情報、とくに入力全体のグローバルな情報を格納するために使います。
注意の受け皿は言語モデルだけでなく、ビジョントランスフォーマーでも観察されています [Darcet+ ICLR 2024]。

ビジョントランスフォーマーでは無情報な背景部分が注意の受け皿として用いられます。
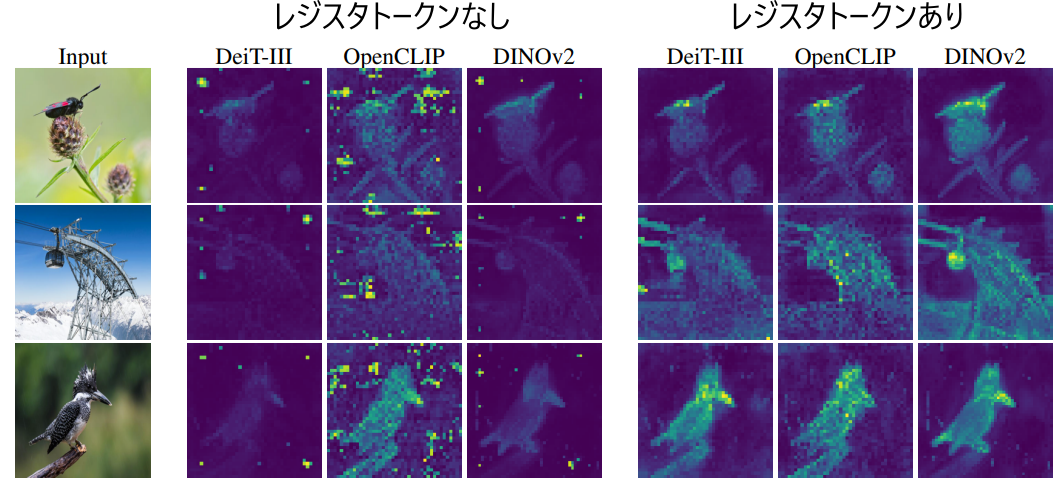
ティモシー・ダルセらはこの注意の受け皿の内部状態をさらに詳しく調べ、受け皿の内部状態はもとのトークンの情報を保持しておらず、画像全体の情報を保持していることを明らかにしました [Darcet+ ICLR 2024]。具体的には、トークンの内部状態だけからトークンの位置やピクセル値を再構成するタスクを解くと、受け皿は通常のトークンよりも成績が悪いです。つまり、受け皿の内部状態はもとのトークンの情報を保持していません。その代わり、トークンの内部状態だけから画像全体のクラスを予測するタスクを解くと、受け皿は通常のトークンよりも成績が良いです。つまり、受け皿の内部状態は画像全体の情報を良く保持しています。
このことは、無情報な背景部分のトークンは情報がないために容量に余裕が生じ、モデルはこの空き地を効率的に活用して入力全体のグローバルな情報を格納するために使っているという仮説を裏付けます。モデルはこのような活用をするように直接訓練されたわけではないですが、自由な探索の結果、このやり方が効果的であることを突き止めてこのような注意パターンを形成するようになったということです。
ティモシー・ダルセらはこの観察をもとに、入力トークンのほか、レジスタトークンという無意味なトークンを数個追加することを提案しました [Darcet+ ICLR 2024]。
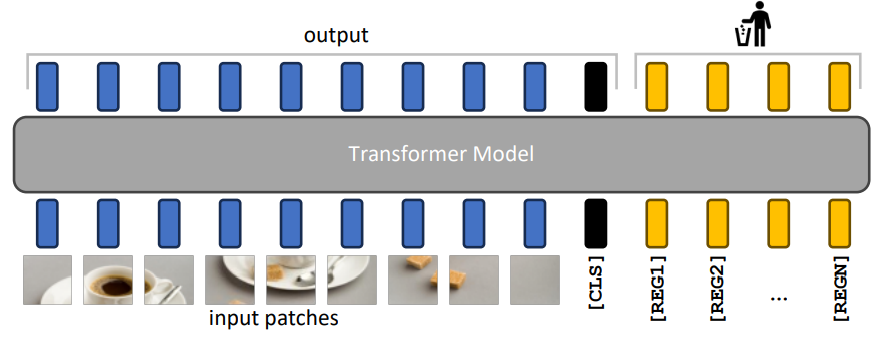
レジスタトークンは無情報な背景部分よりも無意味なので、モデルはこの部分をグローバルな情報を格納するレジスタとして活用するようになると考えられます。背景部分をリサイクル的に受け皿として活用するのは経済的ではありますが、背景部分と言えども多少は情報はあるはずで、そこを受け皿として使うのは詰め込みの結果、情報損失が起こる可能性があります。受け皿として使う専用のレジスタトークンを用意することで、この情報損失を避けられます。
レジスタトークンにより、いくつかのタスクで性能向上することが観察されています。また、追加の利点として、無情報な背景部分に鋭く強い注意を向けることが無くなり、注意の分布が「きれい」で解釈しやすいものになることが観察されています。
レジスタトークンは言語モデル、特にエンコーダー型のモデルで効果的であることが観察されています [Burtsev+ 2020]。デコーダー型、つまり自己回帰型のモデルは前方向にしか注意を向けられず、前に置いたレジスタトークンの内部状態を読み込むことはできても書き込むことができないので、レジスタとして活用することができません。このため、レジスタトークンは主に双方向の注意機構を用いるエンコーダー型のモデルで活用されます。
ここまで、受け皿という特殊な注意先について紹介しました。LLM の注意ヘッドの多くは直近のトークンと受け皿にのみ注意を向け、いくつかのヘッドは特定のルールに基づいて文脈全体からプログラム的に注意先を定めます。次はこの局所的 vs 大域的という軸で注意ヘッド全般の振る舞いを観察します。
逐次ヘッドと検索ヘッド
逐次ヘッド (streaming head) は直近のトークンと受け皿にのみ注意を向けるヘッド、検索ヘッド (retrieval head) は文脈全体から情報を検索し取得する注意ヘッドのことです [Wu+ ICLR 2025, Xiao+ ICLR 2025, Tang+ ICLR 2025]。LLM には一般に、多数の逐次ヘッドと少数の検索ヘッドがあることが観察されています。
前述のように、自己回帰型の言語モデルは受け皿をレジスタとしては活用せず、単に対応先が存在しないときの注意の捨て場として活用すると考えられます。ゆえに逐次ヘッドは基本的に直近のトークンからの情報のみを活用しており、N-gram モデル的な、直近の入力の統計的情報に基づいた振る舞いに対応していると考えられます。喩えるならば深くは考えずに流暢に喋るような役割を持つのが逐次ヘッドです。
一方、検索ヘッドは文脈全体から検索します。今の質問に答えるべき前提をプロンプトやこれまでの発言から情報を取得して長期の一貫性を保つのも検索ヘッドの役割です。喩えるならばルールや論理に基づいてしっかり考えて喋るような役割を持つのが検索ヘッドです。
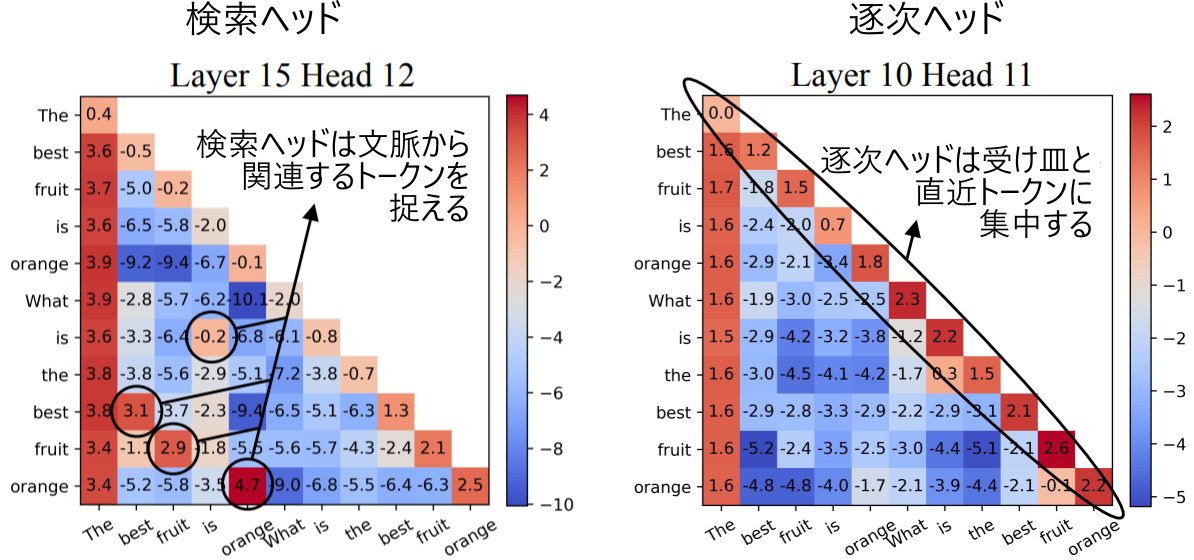
検索ヘッドは文脈内学習にとって極めて重要であることが観察されています。Needle-in-a-Haystack タスクという入力文脈から情報を取得するタスクにおいて、逐次ヘッドを 20 個削除してもほとんど性能は落ちなかったのに対して、検索ヘッドを 20 個削除すると精度が 94.7% → 63.6% と大幅に下落しました [Wu+ ICLR 2025]。ここから、少数の検索ヘッドが LLM における検索を担っていることが示唆されます。
次は代表的な検索ヘッドである帰納ヘッドとその内部のメカニズムについて紹介し、いよいよ LLM の能力の核心に迫っていきます。
帰納ヘッド
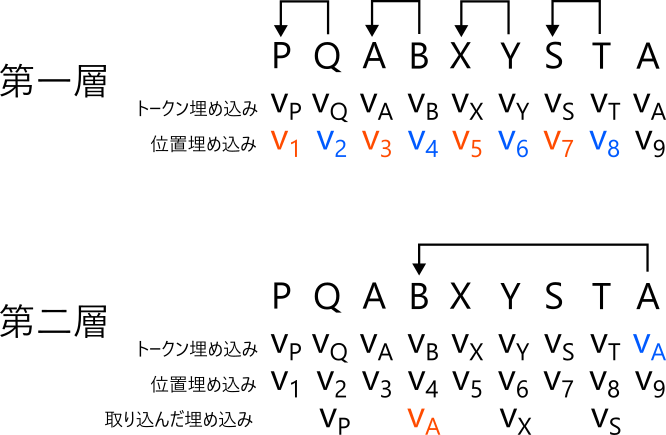
帰納ヘッド (induction head) は ... [A] [B] .... [A] という形式の入力に対して、最新のトークン [A] から [B] に注意を向けるヘッドです [Olsson+ 2022]。つまり過去に同じトークンになったときに次はどうなったかを参照します。例えば以下のようなトークン列が与えられたとすると
| 位置 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| トークン | P | Q | A | B | X | Y | S | T | A |
帰納ヘッドは 9 番目のトークン A から 4 番目のトークン B に注意を向けます。
帰納ヘッドは文脈内学習を実現します。
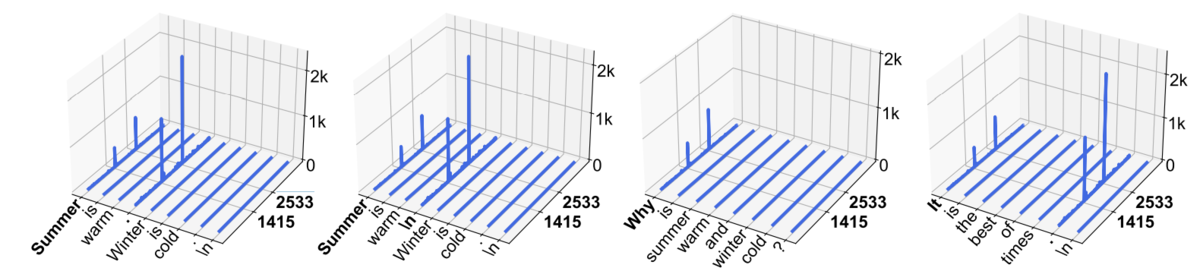
文脈内学習とはプロンプトにいくつかの入出力の例示を与えて、実際に解きたい問題をサポートする手法です。例えば、映画レビューの感情分析タスクを解きたいとき、LLM に判定してほしい本命のレビュー文以外に、人手でつけた例示をいくつか与えます。
とても面白くてエンディングまで一瞬でした!: ポジティブ つまらなさすぎて映写機の前で舞っているホコリを見ていた方が面白かったです。: ネガティブ 見入ってしまってポップコーンを食べるの忘れていたので家で食べました!: ポジティブ スタッフロールが終わってから C パート始まるのやめてほしいです。: ネガティブ とても面白い最高の映画でした!:
この例では「面白い最高の映画でした!」についてラベルを付けたいのですが、単にその例だけを提示するのではなく、こういう場合にはこういうラベルを付けるんだよということを示すために、別の例に対するラベルを前置した上で、LLM に本命データに対する : の続きを生成させます。
文脈内学習の最も単純化した例として
ぶどう: A りんご: A くるま: B たまご: B りんご:
という文脈内学習を考えます。このとき、帰納ヘッドは前回登場した りんご: の次のトークンである A に注意を向け、結果として LLM はテストデータの りんご: に対して A を出力します。
これは入力と全く同じ例示が存在するという理想的な状況ですが、このような状況では帰納ヘッドにより正確にラベルを予測できます。
帰納ヘッドは二層で実現されます。第一層のヘッドは位置埋め込みを用いて一つ前のトークンに注意を向けます。つまり位置が自分と似ているという基準で注意先を決めます。注意先のバリューベクトルを適当に線形変換して自分の内部状態に取り込みます。第二層は取り込んだトークン埋め込みを用いて、一つ前のトークンが自分と似ているかという基準で注意先を決め、帰納ヘッドの注意先に注意を向けます。これは、第一層でのバリューベクトルの線形変換と整合する方向に自身の埋め込みを変換してから注意先を算出すれば実現できます。
このように機械学習モデルに埋め込まれた機構やアルゴリズムを特定することでモデルの理解を得る方法を機構的解釈性 (mechanistic interpretability) といいます。本稿はいわば注意機構を軸にした LLM の機構的解釈性の解説記事です。
ここまでは理想化した状況を考えましたが、... [A'] [B'] .... [A] という形式の入力に対して [A] から [B'] に注意を向けるヘッドのことも帰納ヘッドと呼びます。ここで [A'] は [A] に似たトークンあるいはトークン列です。
前掲の映画レビューの例では、「とても面白い最高の映画でした!:」が [A]、「とても面白くてエンディングまで一瞬でした!:」が [A']、「ポジティブ」が [B'] です。
帰納ヘッドは過去の似た例を検索し、その次トークンを取得します。つまり過去に似た状況になったときに次はどうなったかを参照し、現在の次トークンに役立てます。これにより、LLM はプロンプト中の例示に対して近傍法的な予測アルゴリズムを実行するようになると考えられます。
帰納ヘッドによる文脈内学習により、LLM は近傍法を実行する汎用プラットフォームとして使えるようになります。これによりある意味で外挿が可能になります。
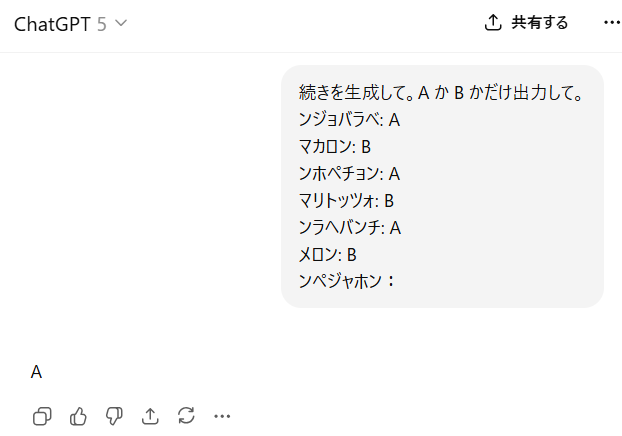
上図はンペジャホンという謎の言葉が A か B に分類する問題の例です。LLM は事前学習でこのような問題を一切見たことがないはずです。ンペジャホンという言葉すら見たことがないはずですし、ンペジャホンに似た言葉を A か B に分類したことも無いはずです。それでも LLM は正しくンペジャホンを A に分類できました。これはある意味で外挿です。
何をもって外挿と言うかは見方の問題です。ンペジャホンという具体例やそれに類似した具体例は LLM は一切見たことが無いでしょう。この意味では外挿です。一方、近傍法やそれに類するアルゴリズムを実行すると予測がうまくいくことが多いということは事前訓練中に何度も遭遇していたに違いなく、それにより帰納ヘッドのように近傍法的なアルゴリズムを実現するようになったと考えられ、実際にそのために今回の予測に成功しています。つまり、表層的なトークンレベルでは外挿、仕組み・アルゴリズムというメタなレベルでは内挿になっています。ただし、メタなレベルまで考え始めると、解決可能なあらゆる問題をこじつけのように内挿と見做してしまえるようになるので、ある問題が内挿か外挿かということを決定することはほとんど意味がなくなり、単に見方の問題になってしまいます。
ここまで、近傍法により文脈内学習を実現する最も基本的な注意ヘッドである帰納ヘッドについて解説しました。しかし、文脈内学習により実現できるのは近傍法だけではありません。次はこの振る舞いを一般化した関数ベクトルについて見ていきます。
関数ベクトル
関数ベクトル (function vector) はタスクを解くための関数を表すベクトルです [Todd+ ICLR 2024]。
文脈内学習は近傍法では解けないタスクも扱います。例えば
short: long common: rare small:
のように対義語に変換するタスクや
amount: cantidad win: ganar dreams:
のように英語をスペイン語に変換するタスクでも文脈内学習が用いられることがあります。しかし、これは似ている例を見つけてその結果をコピーするというアルゴリズムでは解けません。
関数ベクトルは例えば対義語に変換する関数やスペイン語に変換する関数を表すベクトルです。
LLM は文脈に基づいて現在のタスクに対応する関数を構築し、その関数を現在の入力とともに MLP に渡してプログラムを実行し、次トークンを予測します。
エリック・トッドらはこのような仕組みが LLM に存在し、関数がベクトルとして表現されることを実験的に確かめました [Todd+ ICLR 2024]。
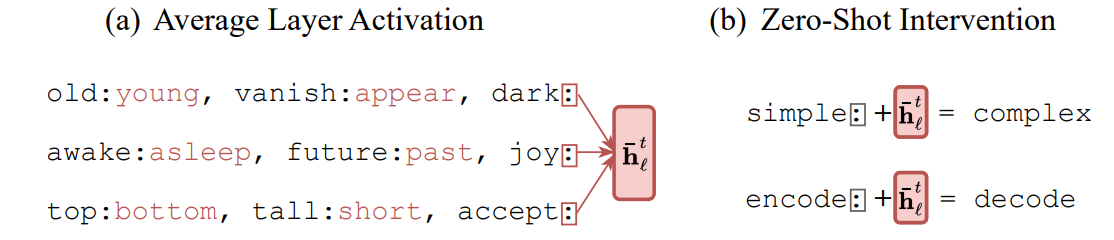
まず、対義語を求めるタスクでいくつかの文脈内学習のプロンプトを入力します。各プロンプトの最後のトークンの内部状態を取り出し平均を取ります。これが対義語を求めるタスクを実現する関数ベクトルです。実際にこのベクトルが対義語を求める関数ベクトルとして機能することは、例示を一切入れず、LLM にトークン: とだけ入力し、このときの内部状態、つまり MLP への入力に関数ベクトルを足し合わせると、このタスクを解くことに成功することから分かります。例えば simple: とだけしか入力しません。何も情報がなければこの続きは何でもあり得ますが、関数ベクトルを MLP への入力に加えると対義語を求める回路が発火して対義語が出力されます。
このような動作は対義語タスクだけでなく、
- 小文字を大文字にするタスク
- 国名を首都名にするタスク
- 英語をフランス語にするタスク
- 現在形を過去形にするタスク
- 単数形を複数形にするタスク
など、様々なタスクにおいて、関数ベクトルの動作が確認されています。このほか、
Monday: Tuesday December: January a: b seven:
のように +1 するタスクというのも関数ベクトルで実現できます。これら全てでモデルは共通であり、つまり MLP も共通であり、MLP は様々な関数ベクトルを受け取り、その関数を実行する汎用変換器、あるいは高階関数のような役割をもつことが示唆されます。
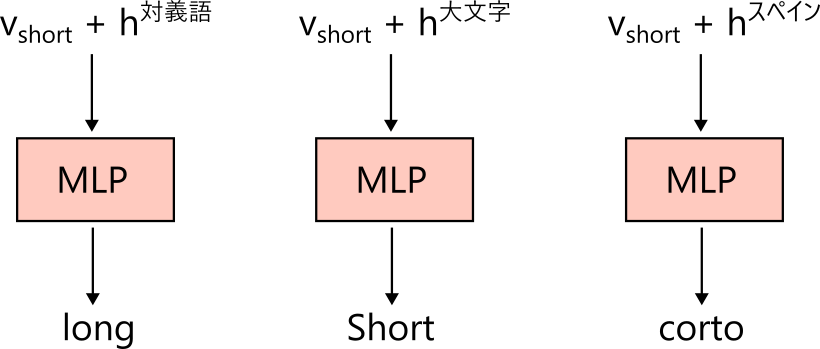
この関数ベクトルはひとたび求まると、文脈内学習以外の状況でも機能します。例えば The word "fast" means を LLM に入力し、means の次トークンを予測するとき、MLP への入力に対義語関数ベクトルを加算すると、The word "fast" means slow という予測となります。これは対義語を計算する回路が発火して対義語の意味を出力してしまったと考えられます。
このほか、
short: Short common: Common small:
のように先頭文字を大文字化するタスクにより大文字化関数ベクトルを求め、The word "fast" means に対して大文字化関数ベクトルを MLP への入力に加算すると次トークンが大文字から始まるようになります。
このようなベクトルは単語ベクトルにおける king - man + woman = queen のような類推を想起するかもしれません。そのような理解はおおよそ正しいのですが、関数ベクトルは必ずしもこのような形だけではありません。例えば対義語関数ベクトル はこのような線形関係ではあり得ません。もし対義語関数ベクトル
を足し合わせることで対義語に変換できるのだとしたら
かつ
より
となってしまいます。ゆえに、対義語関数は単なるベクトルの足し合わせでは実現できず、MLP の内部で非線形な変換を行い実現していると考えられます。
実現方法はタスクが知識依存かそうでないかによってニュアンスが異なります。対義語やスペイン語訳を行う関数は知識依存であり、MLP に含まれるデータベース機能を適宜使いながら関数を実現していると考えられます。このため、データベースに入っていない対義語はうまく変換できない、つまり外挿はできないと考えられます。一方、小文字を大文字にするタスクは純粋に手続き的であり、関数実行はある程度外挿できると期待できます。現在形を過去形にするタスク、単数形を複数形にするタスクなどはその中間であり、ed を付ける、s を付けるなど基本的なルールの適用に関してはある程度外挿できると期待できます。
ここまで、LLM が様々な種類の文脈内学習を行う仕組みについて見てきました。次は LLM のもう一つの大事な能力である思考の連鎖を実現する注意ヘッドについて見ていきます。
反復ヘッド
反復ヘッド (iteration head) は反復的な計算において現在処理中の入力位置に注意を向けるヘッドです [Cabannes + NeurIPS 2024]。反復ヘッドは思考の連鎖 (Chain of Thought) のために重要です。
01 文字列 x を受け取り、1 の個数が偶数か奇数かを予測する問題を考えましょう。0010101001: は 1 が偶数個なので答えは 0(偶数)、1010101001: は 1 が奇数個なので答えは 1(奇数)です。
これを思考の連鎖で解きましょう。 を i 番目までの文字の偶奇とすると
という漸化式(思考の連鎖)で計算できます。これは文字列としては、x と s を連結した文字列で表現できます。0010101001:0011001110 や 1010101001:1100110001 などです。この最後の文字が全ての文字についての偶奇に対応し、つまり入力に対する答えを表します。
ビビアン・カバンヌらはこの 0010101001:0011001110 のような文字列のみでスクラッチからトランスフォーマー言語モデルを訓練し、次トークン予測によりこの問題を解けるようにしました [Cabannes + NeurIPS 2024]。この言語モデルは 0010101001: を入力すると次トークン予測により
0010101001:00010101001:000010101001:0010010101001:00110010101001:001100010101001:0011000010101001:00110010010101001:001100110010101001:0011001110010101001:0011001110
のように問題を解きます。これは思考の連鎖の最もシンプルで純粋な形です。この結果、この言語モデルは未見の 01 文字列にも高い精度で偶奇を計算することができました。内部を分析すると、下記のメカニズムで反復ヘッドが明確に表れていました。
思考の連鎖による の部分はチューリングマシンにおけるテープのような役割を果たします。反復ヘッドが入力から文字を読み込み、MLP が現在の状態と入力の和を計算し、それが新しいテープに書き込まれます。これにより、偶奇を計算するアルゴリズムが実現できます。テープの存在により、注意ヘッドや MLP の内部単体で実現できるよりも複雑なアルゴリズムを実現できます。

反復ヘッドは二層により実現されます。第一層のヘッドはトークン埋め込みを用いてコロン、すなわち入力とテープの境目に注意を向けます。注意先の位置埋め込みをバリューベクトルとして自分の内部状態に取り込みます。次に MLP により、自身の位置埋め込みと取り込んだ位置埋め込みの差 + 1 を計算し、現在の入力位置に対応する位置埋め込みを計算します。第二層は計算した位置埋め込みを用いて、反復ヘッドの注意先に注意を向けます。反復ヘッドは一層だけでは実現困難であることに注意してください。第一層が分かるのは位置埋め込みによると現在何トークン目かということだけです。現在 9 トークン目だったとしても、入力が 6 トークンで 2 トークン処理が終わったところなのか、入力が 5 トークンで 3 トークン処理が終わったところなのか、区別がつきません。第一層でコロンに注意を向けてそこからの距離を計算することで、どこまで処理が済んだかを計算できるようになります。
カバンヌらは訓練した言語モデルの注意先を観察することで、実際にこの方式で反復ヘッドが実現していることを確認しました。
このほか、入力をテープにコピーするタスクや、多項式の漸化式計算などのタスクで同様の反復ヘッドが生まれることを確認しています。
実際の思考の連鎖はこれらのタスクより複雑であり、ポインタが前後に動くことやテープをより消費することなどがある可能性はありますが、本質的にはこのような反復ヘッドとテープのような仕組みで動いていると考えられます。
まとめ
LLM の注意機構には色んな機能があり、注意機構を調べることで LLM の様々な能力の仕組みが明らかになります。
LLM の注意機構は時には単体で、時には MLP や思考の連鎖のテープなどと協調して、ある種のルールやプログラムやアルゴリズムを実現します。LLM はプログラムを実行するための汎用計算装置として働きます。このとき、訓練で全く見たことがない入力に対してもプログラムを実行することで適切に回答を生成できることがあります。つまり、外挿が可能です。また、LLM は単なる関数計算機ではなく、MLP の内部に事前学習で蓄えたデータベースを持つため、対義語を計算する、などのように知識が必要な関数をも実現できます。
LLM がこのような能力を獲得できたのは、第一には注意機構というアーキテクチャが、このようなプログラムを実現しやすい構造にあったということ、第二に、このような能力を獲得すると次トークン予測の精度が質的に改善し、自由な探索の結果、このやり方が最も効果的であることをモデルが突き止めて能力を構築するに至ったということが要因と考えられます。
この第二の観点より、訓練時に役に立ったアルゴリズムしかプログラミングされていない可能性が高く、具体例の単位では外挿をできても、ルールやアルゴリズムのメタレベルでは内挿しかしていないと考えられます。
それでも、具体例レベルでの統計でしか予測ができなかった古典的なモデルと比べると質的に大きな変化であり、プログラムを実行するための汎用計算装置として働けることが、LLM がここまで広く活用される便利なツールになった大きな要素であると考えられます。
もちろん、LLM の内部動作は完全には解明されておらず、本稿で紹介した以外の重要な注意ヘッドがまだ存在しているかもしれず、本稿で紹介したヘッドについても別の説明や解釈が存在する可能性はあります。
本稿をきっかけに、皆さんも LLM の注意機構と能力について考えていただければ幸いです。
著者情報
この記事がためになった・面白かったと思った方は SNS などで感想いただけると嬉しいです。
新着記事やスライドは @joisino_ (Twitter) にて発信しています。ぜひフォローしてくださいね。

佐藤 竜馬(さとう りょうま)
京都大学情報学研究科博士課程修了。博士(情報学)。現在、国立情報学研究所助教。著書に『深層ニューラルネットワークの高速化』『グラフニューラルネットワーク』『最適輸送の理論とアルゴリズム』がある。